如何利用主键索引提高效率
通过本文你可以了解B+树索引的数据结构,计算机系统的内存预读机制,以及不同种类主键对B+树索引的影响从而了解如何利用主键索引提高索引效率。
情景与解决方案
我曾经用SpringBoot与Vue写过一个管理电子书的项目,可以对电子书进行增删改查,主键使用uuid。在初步完成这个项目后,我造了一部分数据去测试系统效率,发现效率并不快,尤其在增加与删除数据时。
而这个效率慢与主键索引有关,这要从MySQL的数据结构说起:
MySQL有多个存储引擎,每种引擎各有特点,从索引角度来说如下:
| 存储引擎 | 索引 |
|---|---|
| memory | hash |
| InnoDB | B+树 |
| MyISAM | B+树 |
更详细的在我这篇文章:MySQL索引数据结构浅聊 | TheSeasonSun
现在最常用的是InnoDB,它的索引为B+树,数据结构如下图:
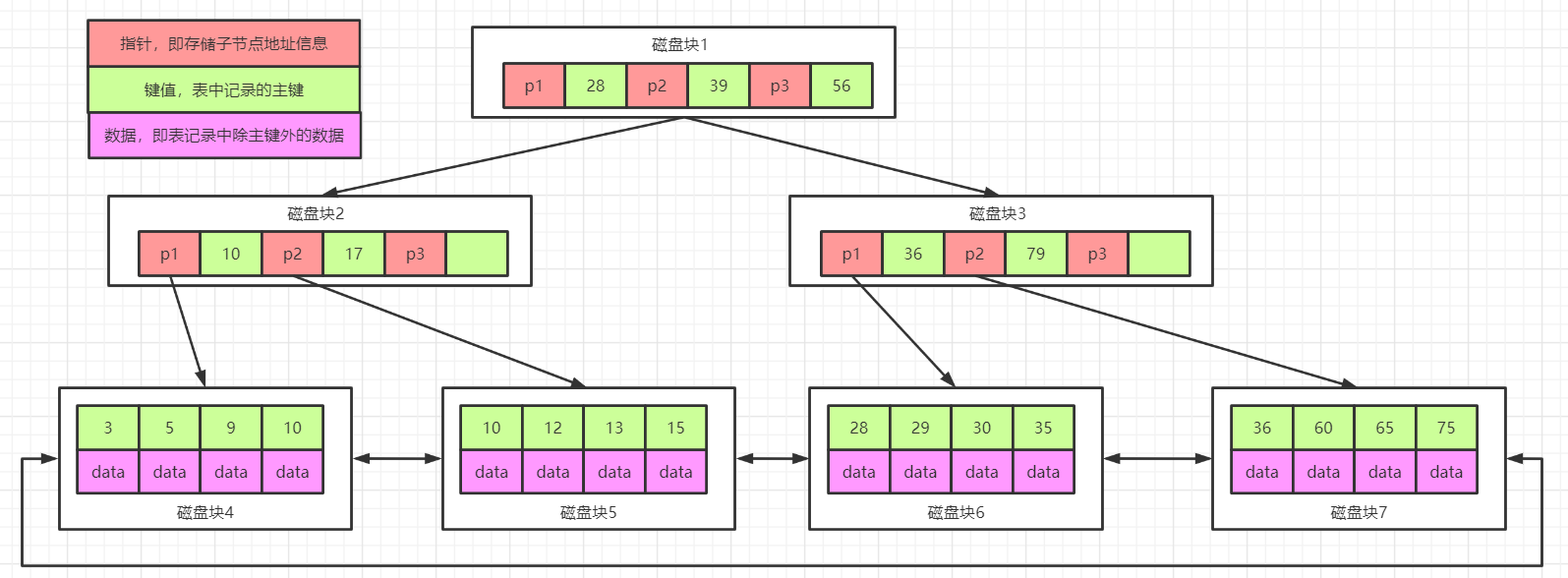
注意:在B+Tree上有两个头指针,一个指向根节点,另一个指向关键字最小的叶子节点,而且所有叶子节点(即数据节点)之间是一种链式环结构。因此B+Tree 支持两种查找运算:一种是对于主键的范围查找和分页查找,另一种是从根节点开始,进行随机查找。
当MySQL借助索引查找某个数据时,现在B+树根节点进行二分查找,找到所查找项对应区间的结点之后继续递归的查找,直到在叶子节点找出Key所对应的data。我们可以发现B+树整个数据结构是有序的,正因如此,插入操作会破坏平衡树的平衡性,因此在进行插入删除操作之后,需要对树进行分裂、合并、旋转等操作来维护平衡性。这也是索引共同的缺点。
那么效率低下的问题我们就可以明白了:uuid是无序的
现在想要提高效率,只能将主键改为自增主键
B+树为了维护索引的有序性,在新插入值时会做必要的维护,常常需要逻辑上挪动后面的数据以腾出位置。这时候会导致页分裂与页合并,插入效率和空间利用率都不高
在当时也曾考虑过加一个自增属性作为Key来创建索引,这种方法或许可以提高查找数据的效率,但本身并不能解决插入效率低的问题,因为在插入数据时依然会维护主键索引,同时多加一个索引消耗的内存是巨大的。而且平时使用主键查找数据时,也可避免回表查询。最后敲定使用雪花算法作为主键(虽然项目只是单体架构)。
怎么选择索引的Key?
对于这个问题,人们的回答众说纷纭,有的人说要易于比较,因为索引查找数据时会把目标Key与B+树上的Key不断比对,所以Key越容易比较,查找效率就越高。有的人说要节省空间,因为索引占用空间与数据相比是巨大的。
我的看法是要根据实际情况决定,以上不论是哪种情况,都是在索引不会有过多改动的前提下的,不然就会出现我上文遇到的插入效率低的问题。当然这都是在目前最常见的B+树索引的情况下
为什么B+树最常用?
因为B+树与其他索引相比,能在占用内存相同的情况下做到效率最高,主要原因从数据结构上来说有一下两点:
- B+ 树有更低的树高
- B+ 树迎合了磁盘预读特性
详情可以看另一篇文章:MySQL索引数据结构浅聊 | TheSeasonSun