并发编程三大特性
并发编程之可见性
加入一个线程t1运行时使用一个变量(把这个变量从主存复制下来存到线程内部),这时线程t2修改了这个变量,但是t1线程无法读到修改后的变量值。这就是线程的不可见性。
1 | /** |
使用volatile,将会强制所有线程都去堆内存中读取running的值
volatile修饰的代码,字节码解释器会有一个叫lock的前置指令修饰,这个lock指令的作用就是:会等待它之前的所有指令完成,并将所有缓冲的写操作写到内存,根据缓存一致性协议,缓存的副本将会失效,并且禁止该指令与其前后的读写指令进行重排序
volatile并不能保证多个线程共同修改running变量时所带来的不一致问题,也就是说volatile不能替代synchronized
volatile
- 保证线程可见性
- MESI
- 缓存一致性协议
- 禁止指令重排序
- DCL单例模式双重校验加volatile
- loadfence原语指令(内存屏障CPU原语)
- storefence原语指令(内存屏障CPU原语)
在变量中加入volatile修饰可以保证线程的可见性,但变量修改时,会同步进t1线程中。另外在某些语句执行的时候(例如println,因为它源码中被synchronized修饰),会触发本地缓存与主内存之间的同步。
volatile修饰引用类型(包括数组)只能保证引用本身的可见性,而不能保证内部字段的可见性。例如:
1 | private static class A{ |
能保证a的可见性,而running不能。
缓存行对齐
- 缓存行对齐
缓存行64个字节是CPU同步的基本单位,缓存行隔离会比伪共享效率要高
Disruptor也是类似写法 - 认识缓存行对齐的编程技巧:因为空间局部性原理,线程读内存数据时会预读它周围内存的数据,而如果多个线程需要的变量恰好相邻(t1需要x1,t2需要x2,x1,x2相邻,t1,t2会把它们都读入线程内),那么线程修改变量的时候,线程之间必须保证缓存一致性,所以会相互同步变量。这个操作也需要消耗资源,减慢效率。
1 | import java.util.concurrent.CountDownLatch; |
注:JUC
tools(工具类):又叫信号量三组工具类,包含有
1)CountDownLatch(闭锁) 是一个同步辅助类,在完成一组正在其他线程中执行的操作之前,它允许一个或多个线程一直等待
2)CyclicBarrier(栅栏) 之所以叫barrier,是因为是一个同步辅助类,允许一组线程互相等待,直到到达某个公共屏障点 ,并且在释放等待线程后可以重用。
3)Semaphore(信号量) 是一个计数信号量,它的本质是一个“共享锁“。信号量维护了一个信号量许可集。线程可以通过调用 acquire()来获取信号量的许可;当信号量中有可用的许可时,线程能获取该许可;否则线程必须等待,直到有可用的许可为止。 线程可以通过release()来释放它所持有的信号量许可。
executor(执行者):是Java里面线程池的顶级接口,但它只是一个执行线程的工具,真正的线程池接口是ExecutorService,里面包含的类有:
1)ScheduledExecutorService 解决那些需要任务重复执行的问题
2)ScheduledThreadPoolExecutor 周期性任务调度的类实现
atomic(原子性包):是JDK提供的一组原子操作类,
包含有AtomicBoolean、AtomicInteger、AtomicIntegerArray等原子变量类,他们的实现原理大多是持有它们各自的对应的类型变量value,而且被volatile关键字修饰了。这样来保证每次一个线程要使用它都会拿到最新的值。
locks(锁包):是JDK提供的锁机制,相比synchronized关键字来进行同步锁,功能更加强大,它为锁提供了一个框架,该框架允许更灵活地使用锁包含的实现类有:
1)ReentrantLock 它是独占锁,是指只能被独自占领,即同一个时间点只能被一个线程锁获取到的锁。
2)ReentrantReadWriteLock 它包括子类ReadLock和WriteLock。ReadLock是共享锁,而WriteLock是独占锁。
3)LockSupport 它具备阻塞线程和解除阻塞线程的功能,并且不会引发死锁。
collections(集合类):主要是提供线程安全的集合, 比如:
1)ArrayList对应的高并发类是CopyOnWriteArrayList,
2)HashSet对应的高并发类是 CopyOnWriteArraySet,
3)HashMap对应的高并发类是ConcurrentHashMap等等
(31条消息) java–JUC快速入门(彻底搞懂JUC)_YANG-Π的博客-CSDN博客_java juc
Contended注解
需要注意,JDK8引入了@sun.misc.Contended注解(只有1.8有),来保证缓存行隔离效果
要使用此注解,必须去掉限制参数:-XX:-RestrictContended
1 | package com.mashibing.juc.c_001_02_FalseSharing; |
并发编程之有序性
为何会存在乱序:为了提高效率
乱序存在的条件:
- as - if - serial 看上去像是序列化(单线程)
- 不影响单线程的最终一致性
对象实例化的过程:
- 申请一个内存,成员变量赋默认值(半初始化状态)
- 调用构造方法,成员变量赋初始值(初始化完成)
- 与引用建立关联
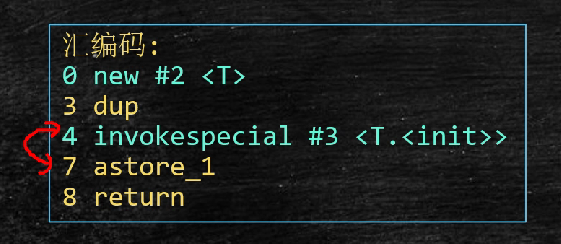
步骤2与步骤3可能会互换顺序,这个现象叫做指令重排,如果在构造方法中new线程同时启动线程,在指令重排的情况下,中间可能this可能会得到值为默认值0的变量,所以不要在构造方法中启动线程。
美团面试题:
- 请解释一下对象的创建过程(半初始化)
- DCL与volatile问题(指令重排)
- 对象在内存中的存储布局(对象与数组的存储不同)
- 对象头具体包括什么(markword klasspointer synchronized)
- 对象怎么定位(直接 间接)
- 对象怎么分配(栈上-线程本地-Eden-Old)
- Object o = new Object() 在内存中占用多少字节?
使用内存屏障阻止乱序执行
内存屏障是特殊指令:看到这种指令,前面的必须执行完,后面的才能执行
intel : lfence sfence mfence(CPU特有指令)
JVM中的内存屏障
所有实现JVM规范的虚拟机,必须实现以下四个屏障:
LoadLoadBarrier LoadStoreBarrier StoreLoadBarrier StoreStorBarriere(Load:读 Store:写)
volatile实现原理
Volatile修饰的变量如下图会建立内存屏障,屏障两边的指令不可以重排!保障有序!

volatile在hotspot中的底层实现
orderaccess_linux_x86.inline.hpp
1 | inline void OrderAccess::fence() { |
LOCK 用于在多处理器中执行指令时对共享内存的独占使用。
它的作用是能够将当前处理器对应缓存的内容刷新到内存,并使其他处理器对应的缓存失效。
另外还提供了有序的指令无法越过这个内存屏障的作用。
并发编程之原子性
race condition: 竞争条件 , 指的是多个线程访问共享数据的时候产生竞争。
在有多线程之间有竞争条件下,可能会导致数据的不一致(unconsistency),比如多个线程操作的变量在并发访问之下产生的不期望出现的结果。
如何保障数据一致?
本质上是线程同步的问题(线程执行的顺序安排好),synchronized可以解决此问题。
synchronized:保证原子性,可见性
monitor (管程),如下代码,synchronized (o)中对象o即为monitor 。
critical section (临界区),如下代码,{}内的部分为临界区。
如果临界区执行时间长,语句多,叫做 锁的粒度比较粗,反之,就是锁的粒度比较细。
1 | synchronized (o) { |
在被synchronized修饰的条件下,多线程竞争临界区的操作,必须要等持有锁的线程执行完,释放锁之后才能由下一个线程去执行。所以临界区的代码都具有原子性,synchronized也是用此方法保证可见性的。
上锁的本质是吧并发编程序列化,上锁的代码这个线程执行完,另一个才能执行。
锁分为两种:
悲观锁:悲观的认为这个操作会被别的线程打断(悲观锁)如:synchronized
乐观锁:乐观的认为这个做不会被别的线程打断(乐观锁 自旋锁 无锁)如:cas操作
CAS = Compare And Set/Swap/Exchange乐观锁:不行就重来!
CAS的深度剖析
CAS:Compare And Set/Exchange,比较并且设定
CAS(V,Expected,NewValue):
if(V == E)
V = New
otherwise try again or fail
CPU原语支持CAS操作
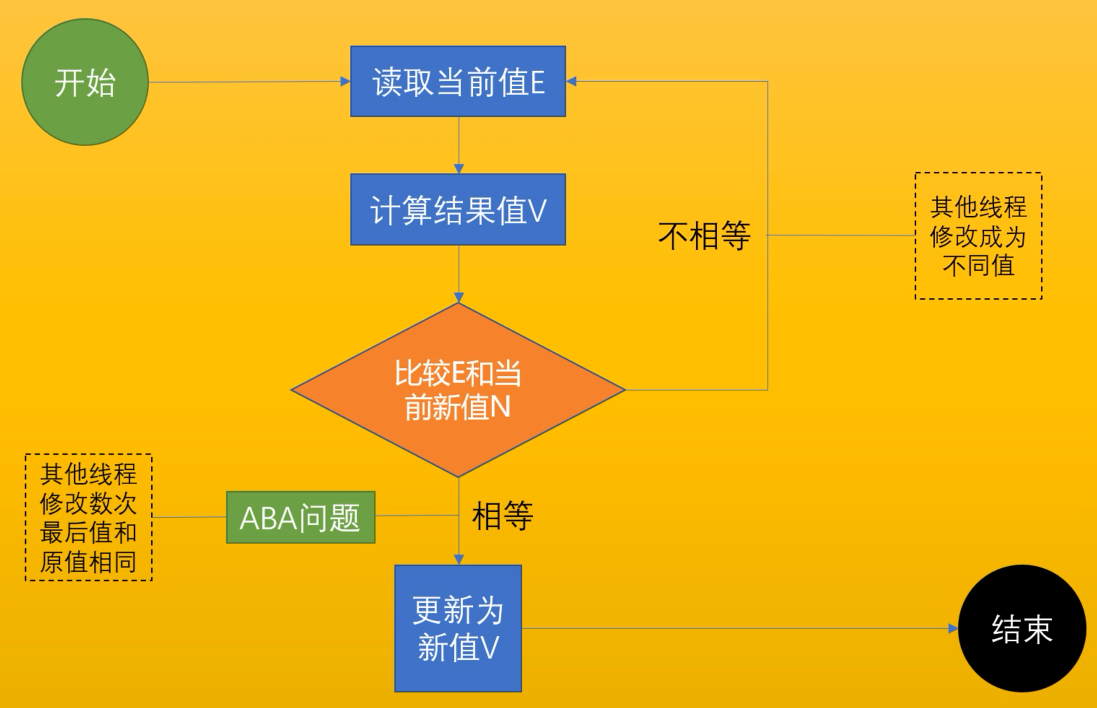
CAS的ABA问题解决方案 - Version
因为CAS判断的过程不能被打断,所以要求CAS本身必须是原子性的
操作系统底层本身也支持CAS
从AtomicInteger入手深入源码剖析CAS
AtomicInteger:
1 | public final int incrementAndGet() { |
Unsafe:
1 | public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5); |
运用:
1 | package com.mashibing.jol; |
jdk8u: unsafe.cpp:
cmpxchg = compare and exchange set swap
1 | UNSAFE_ENTRY(jboolean, Unsafe_CompareAndSwapInt(JNIEnv *env, jobject unsafe, jobject obj, jlong offset, jint e, jint x)) |
jdk8u: atomic_linux_x86.inline.hpp 93行
is_MP = Multi Processors (CPU多核)
1 | inline jint Atomic::cmpxchg (jint exchange_value, volatile jint* dest, jint compare_value) { |
jdk8u: os.hpp is_MP()
1 | static inline bool is_MP() { |
jdk8u: atomic_linux_x86.inline.hpp
1 |
最终实现:
cmpxchg = cas修改变量值
cmpxchg 在汇编语句上不是原子性的,所以加上了lock
1 | lock cmpxchg 指令 |
硬件:
lock指令在执行的时候视情况采用缓存锁或者总线锁,如上lock cmpxchg 指令,某个CPU在改动内存的值的时候,会把总线(或其他什么东西)锁上,等CPU改动完并返回之后再解开锁。所以CAS说是乐观锁,但在底层的实现还是很像悲观锁。
乐观锁效率不一定比悲观锁高,
如果临界区执行时间比较长,等的线程又很多 -> 重量级
时间短,等的线程少 -> 自旋锁
synchronized如何保障可见性?
解锁之后,要把内存的状态与本地的缓存做一次刷新对比,之后下个线程才会继续